
Illustrated by. Paul Tebbott
SELECT문은 데이터베이스에 있는 데이터를 선택하고자 할 때 쓰인다. 이 구문으로 데이터를 가져오기 위해서는 최소 두가지 정보(1. 무엇을 2. 어디에서 가져오는지)를 입력해야 한다.
개인적으로 RDBMS는 MySQL을 사용하고 있다. 행여 이 포스트를 읽는 독자가 다른 RDBMS(PostgreSQL, MariaDB, SQLite, IBM DB..etc)를 사용하더라도 걱정할 필요는 없다. 대부분의 RDMBS에서 적용가능한 문법을 사용하였기 때문이다.
만약 실습시 사용할 Database가 없다면 Github에 공유되어 있는 Sample Database를 이용하면 된다. Sample Data사용법은 아래 Sample Database 부분을 참고하자.
* 실습을 진행할 개인의 Database가 있다면 Sample Database 부분은 건너 뛰면 된다.
* Sample Database 는 Patrick Crews 와 Giuseppe Maxia 가 만들었다.
Table of Contents
- Sample Database
- Single Column
- Multi Column
- All Column
- Eliminating Duplicate Row
- Specific Value
- Sorting Rows
- Show Limited Rows
- Counting Rows
- Reference
Sample Database
Sample Data를 사용하기 위해 거쳐야 하는 스탭은 아래와 같다.
- Repository 다운로드
- Repository를 다운로드한 디렉토리(폴더)로 이동
- MySQL 에 Database Import
- Validating Data
- DB 사용
mysql -u userName -p -t < employees.sql+-----------------------------+ | INFO | +-----------------------------+ | CREATING DATABASE STRUCTURE | +-----------------------------+ +------------------------+ | INFO | +------------------------+ | storage engine: InnoDB | +------------------------+ +---------------------+ | INFO | +---------------------+ | LOADING departments | +---------------------+ +-------------------+ | INFO | +-------------------+ | LOADING employees | +-------------------+ +------------------+ | INFO | +------------------+ | LOADING dept_emp | +------------------+ +----------------------+ | INFO | +----------------------+ | LOADING dept_manager | +----------------------+ +----------------+ | INFO | +----------------+ | LOADING titles | +----------------+ +------------------+ | INFO | +------------------+ | LOADING salaries | +------------------+ | cs |
time mysql -u root -p -t < test_employees_md5.sql+----------------------+ | INFO | +----------------------+ | TESTING INSTALLATION | +----------------------+ +--------------+------------------+----------------------------------+ | table_name | expected_records | expected_crc | +--------------+------------------+----------------------------------+ | employees | 300024 | 4ec56ab5ba37218d187cf6ab09ce1aa1 | | departments | 9 | d1af5e170d2d1591d776d5638d71fc5f | | dept_manager | 24 | 8720e2f0853ac9096b689c14664f847e | | dept_emp | 331603 | ccf6fe516f990bdaa49713fc478701b7 | | titles | 443308 | bfa016c472df68e70a03facafa1bc0a8 | | salaries | 2844047 | fd220654e95aea1b169624ffe3fca934 | +--------------+------------------+----------------------------------+ +--------------+------------------+----------------------------------+ | table_name | found_records | found_crc | +--------------+------------------+----------------------------------+ | employees | 300024 | 4ec56ab5ba37218d187cf6ab09ce1aa1 | | departments | 9 | d1af5e170d2d1591d776d5638d71fc5f | | dept_manager | 24 | 8720e2f0853ac9096b689c14664f847e | | dept_emp | 331603 | ccf6fe516f990bdaa49713fc478701b7 | | titles | 443308 | bfa016c472df68e70a03facafa1bc0a8 | | salaries | 2844047 | fd220654e95aea1b169624ffe3fca934 | +--------------+------------------+----------------------------------+ +--------------+---------------+-----------+ | table_name | records_match | crc_match | +--------------+---------------+-----------+ | employees | OK | ok | | departments | OK | ok | | dept_manager | OK | ok | | dept_emp | OK | ok | | titles | OK | ok | | salaries | OK | ok | +--------------+---------------+-----------+ +------------------+ | computation_time | +------------------+ | 00:00:32 | +------------------+ +---------+--------+ | summary | result | +---------+--------+ | CRC | OK | | count | OK | +---------+--------+ - |
show databases;
+--------------------+ | Database | +--------------------+ | employees | | information_schema | | mysql | | werbnb | | performance_schema | | sys | | wecodi | +--------------------+ |
use employees;
Database changed |
show tables;
+----------------------+ | Tables_in_employees | +----------------------+ | current_dept_emp | | departments | | dept_emp | | dept_emp_latest_date | | dept_manager | | employees | | salaries | | titles | +----------------------+ 8 rows in set (0.02 sec) |
Single Column
-- SYNTAX SELECT columnName FROM tableName; |
한 개의 column 선택하기
/* employees 라는 table 에서 birth_date 이라는 Column을 선택 */ SELECT birth_date FROM employees; -- RESULT +------------+ | birth_date | +------------+ | 1953-09-02 | | 1964-06-02 | | 1959-12-03 | | 1954-05-01 | | 1955-01-21 | +------------+ |
Multi Column
-- SYNTAX SELECT columnName FROM tableName; |
두개 이상의 column 선택하기
*주의*
마지막 column뒤에는 , 를 붙이면 안된다. 이를 어길시 에러가 발생한다. 반드시 column과 cloumn 사이에만 comma를 붙이도록 하자
/* employees 라는 table 에서 first_name 과 last_name 을 선택 */ SELECT first_name, last_name FROM employees; -- RESULT +------------+-----------+ | first_name | last_name | +------------+-----------+ | Georgi | Facello | | Bezalel | Simmel | | Parto | Bamford | | Chirstian | Koblick | | Kyoichi | Maliniak | +------------+-----------+ |
All Column
-- SYNTAX SELET * FROM tableName; |
모든 Column 선택하기
Column 을 일일이 나열하기보단 Asterisk(*) 를 사용하자. 만약 정렬을 하지 않았다면 삽입된 순서대로 반환된다.
/* employees 라는 table의 모든 컬럼 선택 */ SELECT * FROM employees; -- RESULT +--------+------------+------------+-----------+--------+------------+ | emp_no | birth_date | first_name | last_name | gender | hire_date | +--------+------------+------------+-----------+--------+------------+ | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | | 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | | 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | | 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | +--------+------------+------------+-----------+--------+------------+ |
Eliminating Duplicate Row
-- SYNTAX SELECT DISTINCT columnName FROM tableName; |
중복된 값 제외하여 출력하기
- DISTINCT 키워드를 이용하여 중복값을 제거한다.
- 이 키워드는 column명 앞에 적어주어야 한다.
- DISTINT 키워드는 모든 column에 적용된다. 하나의 컬럼에만 적용할수 없다.
/* titles 테이블에서 중복된 값을 제외한 title 가져오기 */ SELECT DISTINCT title FROM titles; -- RESULT +--------------------+ | title | +--------------------+ | Senior Engineer | | Staff | | Engineer | | Senior Staff | | Assistant Engineer | | Technique Leader | | Manager | +--------------------+ |
만약 DISTINCT 키워드를 이용하지 않았다면 아래와 같이 불필요한 rows를 모두(443308 rows) 가져오게 될 것이다. OMG.....
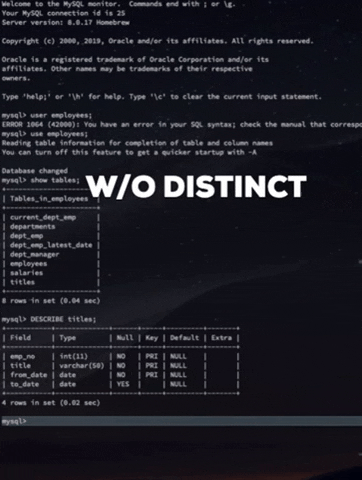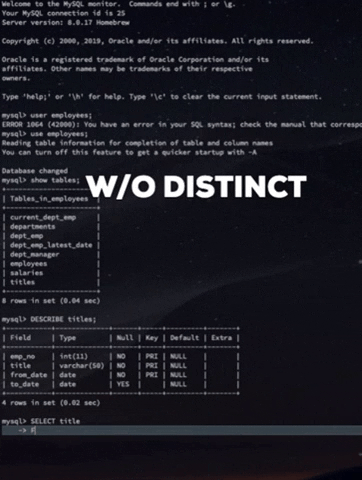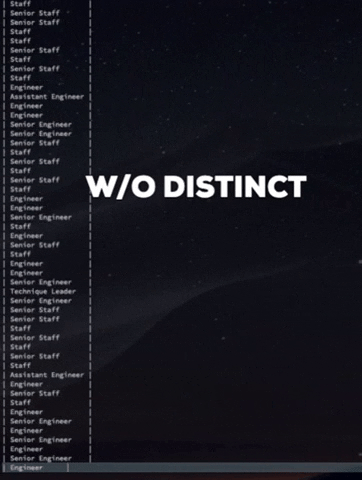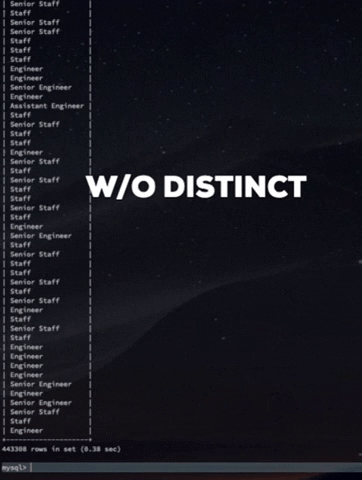
W/O DISTINCT keyword
Specific Value
-- SYNTAX SELECT columnName1, columnName2 FROM tableName WHERE columnName = 'value'; |
특정 값 선택하기
/* employees 테이블에서 first_name이 Danny라는 직원 선택 first_name과 last_name 출력 */ SELECT first_name, last_name FROM employees WHERE first_name = 'Danny'; -- RESULT +------------+-----------+ | first_name | last_name | +------------+-----------+ | Danny | Berendt | | Danny | Shihab | | Danny | Nyanchama | | Danny | Vuskovic | | Danny | Zizka | +------------+-----------+ |
Sorting Rows
-- SYNTAX SELECT columnName1, columnName2 FROM tableName ORDER BY filteringColumn; |
오름차 순으로 정렬
/* salaries 테이블에서 salary가 낮은 순으로 정렬한 데이터중 emp_no 와 salary만 출력 */ SELECT emp_no, salary FROM salaries ORDER BY salary; -- RESULT +--------+--------+ | emp_no | salary | +--------+--------+ | 253406 | 38623 | | 49239 | 38735 | | 281546 | 38786 | | 15830 | 38812 | | 64198 | 38836 | +--------+--------+ |
-- SYNTAX SELECT columnName1, columnName2 FROM tableName ORDER BY filteringColumn DESC; |
내림차 순으로 정렬
/* salaries 테이블에서 salary가 높은순으로 정렬한 데이터중 emp_no 와 salary만 출력 */ SELECT emp_no, salary FROM salaries ORDER BY salary DESC; -- RESULT +--------+--------+ | emp_no | salary | +--------+--------+ | 43624 | 158220 | | 43624 | 157821 | | 254466 | 156286 | | 47978 | 155709 | | 253939 | 155513 | +--------+--------+ |
Show Limited Rows
-- SYNTAX SELECT columnName FROM tableName LIMIT #; |
한정된 #만큼의 rows 선택하기
원하는 개수만큼의 rows를 선택하는 문법은 RDBMS 마다 차이가 있다.
LIMIT 이라는 키워드는 MySQL, MariaDB, PostgreSQL 그리고 SQLite에서 사용 가능하다.
- Oracle : ROWNUM
- Microsoft Access & Microsoft SQL Server: TOP
- DB2 : FETCH FIRST
ROWNUM <= #
TOP #
FETCH FIRST # ROWS ONLY
/* departments 테이블에 속한 모든 컬럼중 5개 row만 가져오기 (오름차순) */ SELECT * FROM departments LIMIT 5; -- RESULT +---------+------------------+ | dept_no | dept_name | +---------+------------------+ | d009 | Customer Service | | d005 | Development | | d002 | Finance | | d003 | Human Resources | | d001 | Marketing | +---------+------------------+ |
/* titles 테이블에 속한 모든 컬럼중 title 기준으로 내림차순으로 정렬한 10개 row만 가져오기 */ SELECT * FROM titles ORDER BY title DESC LIMIT 10; -- RESULT +--------+------------------+------------+------------+ | emp_no | title | from_date | to_date | +--------+------------------+------------+------------+ | 10129 | Technique Leader | 1996-01-16 | 9999-01-01 | | 10070 | Technique Leader | 1985-10-14 | 9999-01-01 | | 10033 | Technique Leader | 1987-03-18 | 1993-03-24 | | 10074 | Technique Leader | 1990-08-13 | 9999-01-01 | | 10021 | Technique Leader | 1988-02-10 | 2002-07-15 | | 10044 | Technique Leader | 1994-05-21 | 9999-01-01 | | 10069 | Technique Leader | 1992-06-14 | 9999-01-01 | | 10079 | Technique Leader | 1995-12-13 | 9999-01-01 | | 10122 | Technique Leader | 1998-08-06 | 9999-01-01 | | 10025 | Technique Leader | 1987-08-17 | 1997-10-15 | +--------+------------------+------------+------------+ |
Counting Rows
-- SYNTAX SELECT COUNT(*) FROM tableName; |
특정한 테이블의 총 row 개수 세기
/* employees 테이블의 총 row 수 가져오기 */ SELECT COUNT(*) FROM employees; -- RESULT +----------+ | COUNT(*) | +----------+ | 300024 | +----------+ |
이로써 기본적인 SELECT문의 사용법을 알아보았다.
Reference