
About DOM
D: Document 문서 | O: Object 객체 | M: Model 모델
호흡있는 모든 것들은 눈에 보이는것과 보이지 않는 것에 둘러쌓여 하루를 살아간다.
우리는 눈에 보이지 않는 것들(예를들어 마음, 생각, 추상적인 개념들)을 시각화 하기를 좋아한다. 그로 인해 보이지 않는 것들이 형상을 갖추게 되고 이를 이해하기가 훨씬 수월해지게 된다. 수학자들은 수학적인 기호들(+, -, %)을 음악가들은 음표들(♬, ♪, ♫) 그리고 프로그래머들은 코드( <, >, #, &)와 일상을 공유하며 살아간다.
오늘 우리가 보게될 DOM은 Tree형태의 구조를 이루고 있다. DOM은 객체로 모델링된 문서이다. Document가 지칭하는 문서는 HTML, XML과 같은 웹 문서이다. 객체화 시키는 것들은 웹문서를 구성하는 모든것(element, attribute, content...etc)이다.
그렇담 객체화 시키는 이유가 무엇일까?
단순 Text 형태인 HTML을 객체화 시킴으로써 프로그래밍 언어를 이용한 접근이 용이해지기 때문이다. 그로인해 프로그래머들은 객체화된 HTML의 구성요들을 자유자재로 다룰 수 있게 된다.
DOM은 프로그래밍 언어와 독립적이다. 프로그래밍 언어와 독립적이라는 말은 어느 한 특정 언어에 종속되지 않고 다양한 언어로 DOM을 다룰 수 있다는 말이다.
DOM Tree
DOM Tree 가 만들어지는 과정을 살펴보기 위해서는 브라우저가 동작하는 원리에 대한 이해가 필요하다.
브라우저 동작원리에 대한 자세한 내용은 다른 포스트에서 다루기로 하겠다.
DOM Tree가 만들어지기위해 거치는 과정을 간단하게만 살펴보자. 웹에 Web resource(HTMl, XML, Images etc)를 나태내는 과정은 생각외로 여러 작업 과정을 거치게 된다.
Web resource: 웹 리소스라는 것은 WWW 로부터 얻을 수 있는 모든 자원을 말한다.
브라우저는 웹 리소스를 화면에 그리는 기능을 한다. HTML과 CSS파일들이 Display 되는 과정을 아래 그림을 통해 살짝 엿보자.
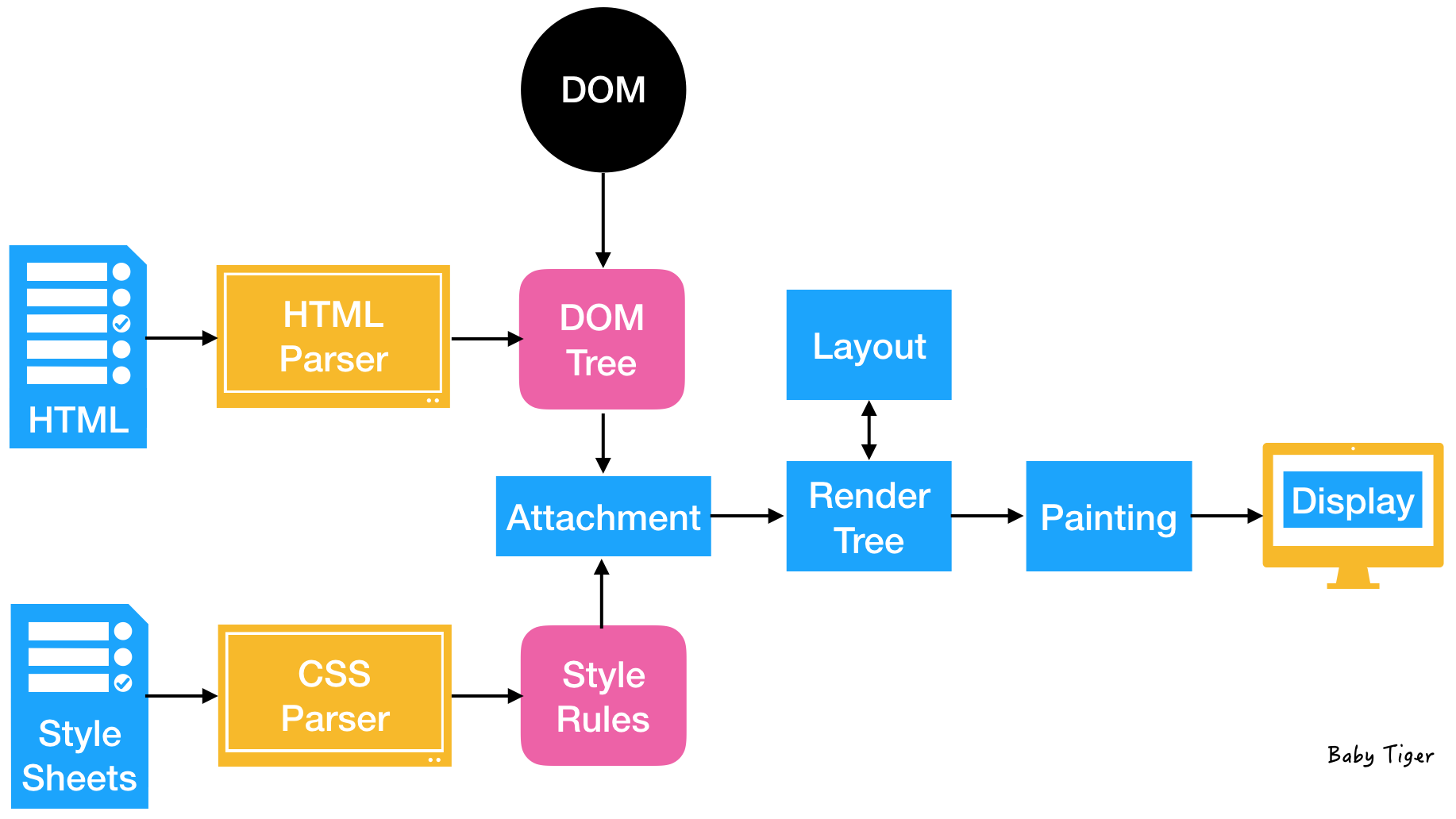
노란 박스를 보라. HTML parser와, CSS parser 이다. 이들은 각각의 문서를 파싱하는 역할을 한다. HTML parser는 HTML을 DOM Tree로 파싱하고, CSS parser는 Style Sheets을 Style Rules로 파싱한다.
Parsing: 코드를 사용할 수 있도록 특정 형식으로 변환하는 것
DOM tree 가 형성이 되는 과정을 Step by Step으로 정리해보자면 아래와 같다.
- Browser가 서버로부터 받은 HTML문서를 읽음
- 어떤 것을 Parsing 할지 결정함
- Parsing
이 과정을 통해 tag로 구성되어 있는 HTML을 객체 기반의 DOM으로 전환시키며 Render Tree가 형성이된다.
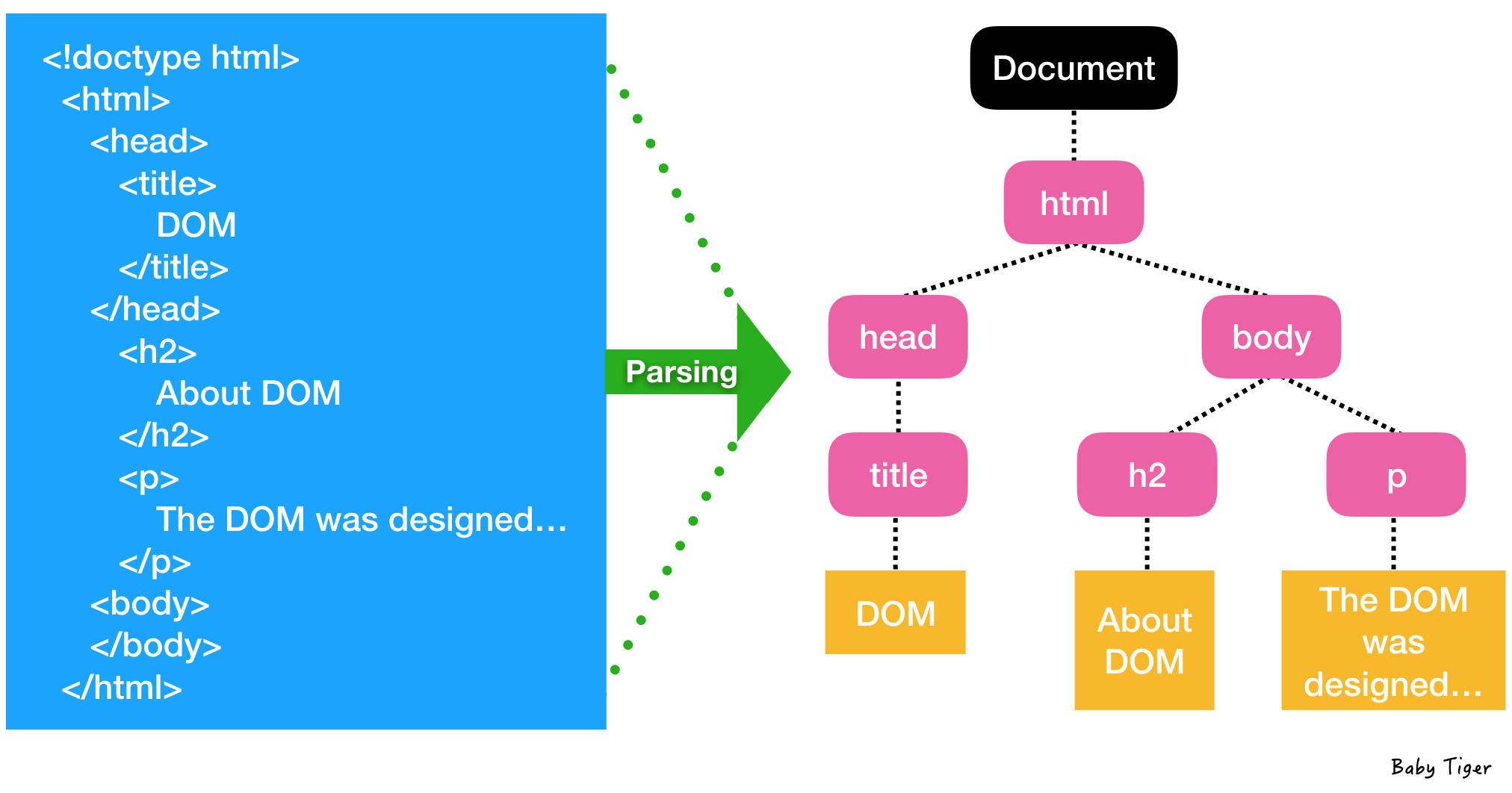
HTML의 tag들이 Parsing 과정을 거쳐 부모 자식의 관계로 변하였다. DOM Tree의 구조를 좀더 세밀히 관찰해보자.
DOM Tree Stucture
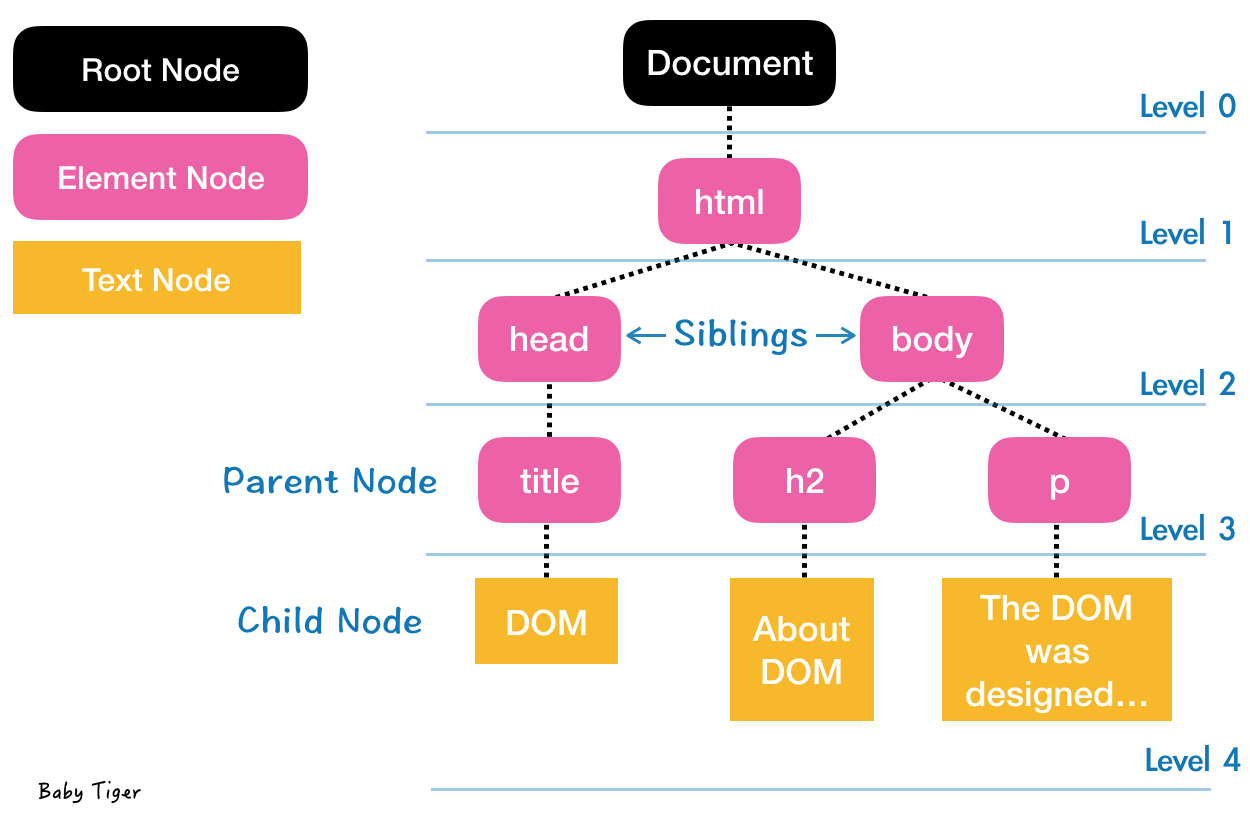
모든 객체들을 node라고 부를 수 있다. 위의 예시에서는 Root Node, Element Node, 그리고 Text Node가 존재한다. 제일 상단에 있는 Root Node는 단 하나만 존재하며 DOM Tree에서의 root node는 Document 이다. 본래의 <html>, <head>, <body> 등등은 element node로 불리운다. HTML에서 content 였던 부분은 text node라 지칭한다.
Tree 구조는 깊이에 따라 level(층)을 나눈다. Level 0 에는 document가 Level 1 에는 html이 Level 2 에는 head와 body, Level 3 에서는 title, h2, 그리고 p가 Level 4에는 text node들이 위치해 있다.
자신과 연결된 바로 윗 level에 있는 노드를 '부모 노드'라 부르고 자신과 연결된 아래 level에 있는 노드를 '자식 노드'라 부른다. 같은 층에 있는 노드는 '형제 노드'이다. 자신기준으로 한 층 이상 차이나는 노드는 '조상 노드'라 일컫는다.
이를 정리해보자면, title은 DOM의 부모노드, DOM은 title의 자식노드, head와 body는 서로간의 형제노드, html은 DOM의 조상노드이다.
DOM 다루기
이제부터는 DOM을 통해 HTML문서를 추가, 수정, 삭제하는 법을 알아보자.
아래 주어진 방법들을 이용하여 직접 브라우저 콜솔창에서 시험해보라.
Access Elements
특정 요소를 다루기위해 접근하는 다양한 방법.
id 를 통해 접근 : getElementById(id)
Id 이름으로 찾은 element 를 리턴해준다.
tag 를 통해 접근 : getElementsByTagName(tagName)
class 를 통해 접근 : getElementsByClassName(className)
*여기서 주의해야 할점은 Element가 단수형인가? 복수형인가? 이다. id는 전체 문서에서 유일무이하기 때문에 단수로 써주어야 하고 tag와 class는 같은 이름으로 여러개 존재 할 수 있기에 복수형으로 취급해 주어야한다.

Get Content of an Element
컨텐츠를 변경하고자 할 때 사용.
Contents 변경하기 01 : innerHTML
Contents 변경하기 02 : textContent
컨텐츠를 변경하는 방법은 innerHTML 과 textContent사용법이 있다. 아래의 예시를 통해 둘의 차이를 알아보자.
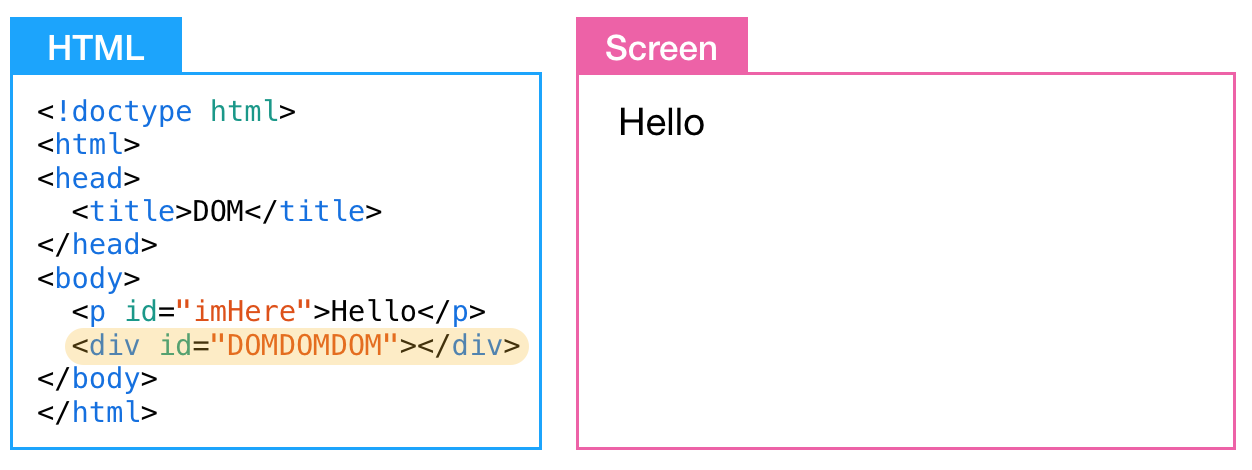
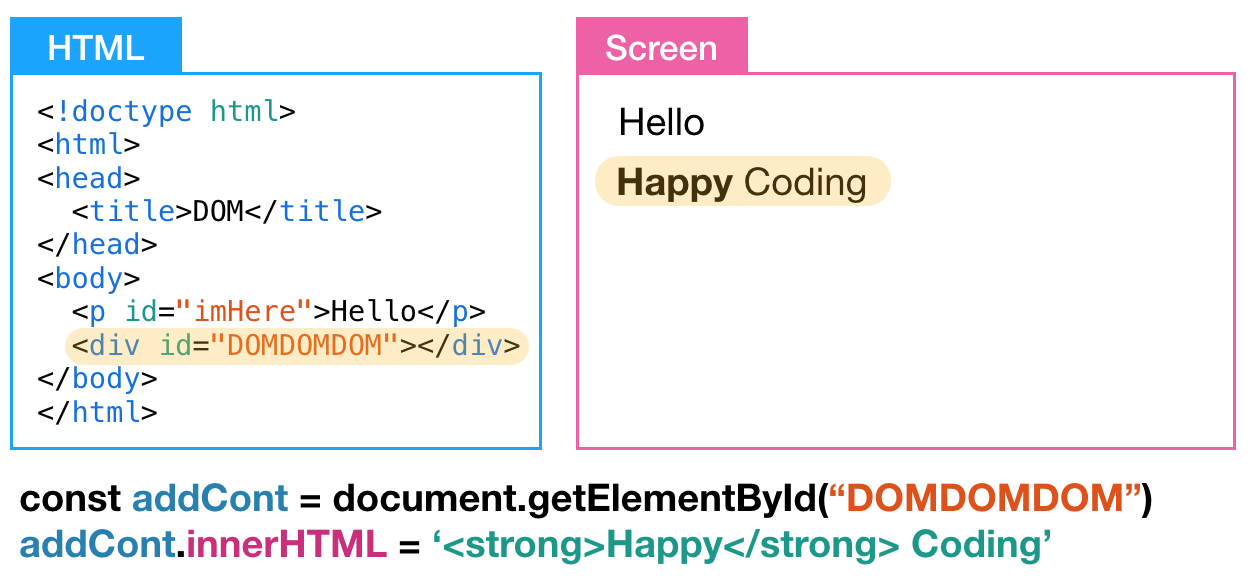
추가될 content는 "Happy Coding"이다. 여기서 Happy는 진하게 나타내고 싶다.
먼저 textContent를 사용해보겠다.

화면에 <strong>이라는 태그가 함께 나타나게 되었다....
이처럼 textContent는 string안의 태그를 인식하지 못한다
그럼 다음으로는 innerHTML을 이용해 보겠다.
Changing Elements
요소를 변경하고자 할 때 사용.
Attribute 변경하기 : element.attributes
요소의 스타일 변경하기 : element.style.property
Adding and Deleting Elements
요소를 추가하거나 지울때 사용.
HTML 요소 만들기 : createElement(element)
자식노드 삭제하기 : removeChild(element)
자식노드로 추가하기 : appendChild(element)
자식노드 교체하기 : replaceChild(element)
Reference
JavaScript HTML DOM Document
Walking the DOM
Creating HTML Elements with JavaScript
Understanding the DOM — Document Object Model
DOM 소개
Document Object Model Activity Statement
Modeling, DOM and HTML parser