
Illustrated by. Alex S. Mostov
2019년, 올 한해도 열심히 보낸 초코는 자신에게 일주일 여행이라는 포상을 주고자 한다. 목적지는 20대를 보낸 그리운 캘리포니아.
Googling 하여 찾은 저렴한 가격의 비행기표와 Airbnb를 통해 정한 숙소, 그리고 Enterprise에서 고른 렌트카를 크래딧 카드로 결제하였다. 그 후, SNS를 통해 미국에 있는 보고픈 친구들에게 여행 기간을 DM으로 보내었다.

문명견이자 현대견인 초코가 한 행동들은 데이터베이스와 밀접한 연관성을 가진다. 컴퓨터와 함께 발전해온 데이터베이스로 인해 우리는 일상을 더 편리하고 글로벌하고 스마트하게 영위할 수 있게 되었다.

burleighcreate, Adrew McKay,
Michael Hacker, Lettera P megazine
이번 포스팅에서는 일, 의사소통, 쇼핑 그리고 여가등 삶의 모든면에서 우리 삶을 윤택하게하는 데이터베이스에 대해 알아보도록 하겠다.
Table of Contents
링크를 클릭하면 해당 내용으로 이동합니다
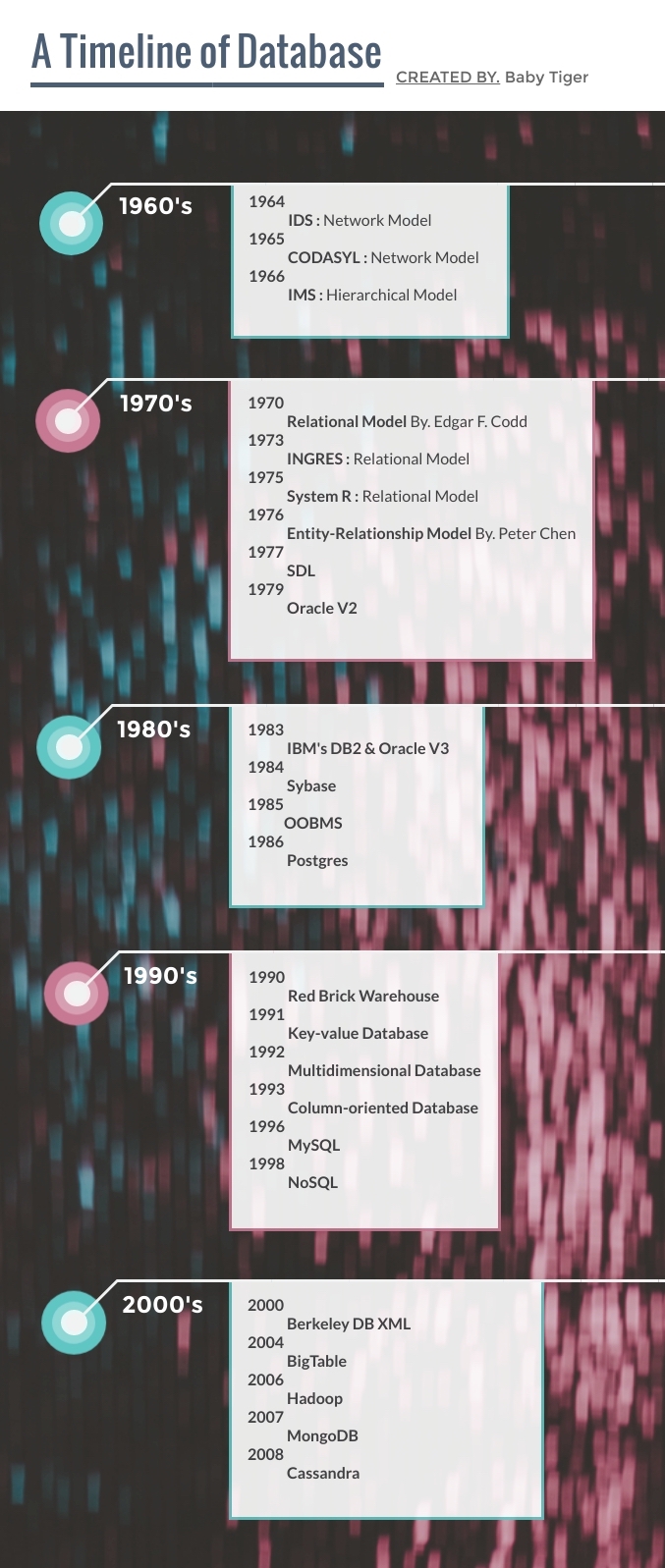
- About Database
DB의 개념과 특징 - History of Database
Pre-computer DBMS 이전
1960s HW의 발전 그리고 DB의 등장
1970s RDBMS의 탄생
1980s SQL과 RDBMS의 성공
1990s 인터넷 보급으로 인한 데이터의 팽창
2000s Big Three : Microsoft, IBM, Oracle
Today 2019 DB Trend
- References
About Database
데이터베이스(DB)는 일정 시간 동안 수집된 데이터들을 담고 있다. 데이터는 끊임 없이 생성된다. 인간의 두뇌는 모든 데이터를 기억하는데에 한계가 있기에 도구의 도움을 필요로 한다. 필요한 정보를 종이에 기록한다고 하더라도 공간적 제약, 공유성의 한계가 발생한다. DB를 사용하게 된다면 위와 같은 제약을 극복할 수 있고 다양한 혜택을 누릴 수 있다.
- 많은 양의 데이터를 적은 공간에 저장할 수 있음
- 검색을 빠르고 쉽게 할 수 있음
- 데이터를 수정하거나 삭제하기 쉬움
- 데이터를 쉽게 정렬할 수 있음
- 수많은 사람들이 동시에 필요한 데이터에 접근할 수 있음
데이터베이스에 있는 데이터들을 사용하기 위해서는 DBMS(데이터베이스 관리 시스템)가 필요하다. 우리는 데이터베이스 시스템을 통해 필요한 데이터를 검색하고 변경할 수 있다.
DB의 개념
DB의 네가지 개념
- Integrated Data 통합된 데이터 여러곳에서 나누어 사용하던 데이터를 하나로 통합하는 것을 말한다. 중복을 최소화 시켜야 한다.
- Stored Data 저장된 데이터 문서로 보관하는 것이 아닌 디스크와 같은 컴퓨터 저장장치에 저장하는 것을 말한다.
- Operational Data 운영 데이터 병원, 항공사, 도서관 처럼 특정 조직을 운영하기 위한 목적을 위해 사용되는 데이터를 말한다. 목적없이 단순히 저장되어 입출력되는 데이터는 운영 데이터라고 말하지 않는다.
- Shared Data 공용 데이터 한사람이나 한가지 업무만을 위해 사용되는 데이터가 아닌 공동으로 사용되는 데이터를 말한다. 같은 데이터를 동시에 다수가 사용 가능해야 한다.
DB의 특징
모든 DB는 다음과 같은 특징을 갖고 있다.
- Real Time Accessibility 실시간 접근성 실시간이라는 용어의 의미가 내포하는 것 처럼 사용자가 요청하면 그 순간 원하는 데이터를 보내줘야 한다.
- Continuous Change 계속적인 변화 데이터는 시간이 흐름에 따라 변경되기 마련이다. 데이터베이스는 바뀐 데이터의 값을 insert, delete, update를 통해 변경할 수 있어야 한다.
- Concurrent Sharing 동시 공유 데이터베이스에 있는 데이터는 여러 사용자에게 동시에 공유될 수 있어야 한다.
- Reference by Content 내용에 따른 참조 사용자가 원하는 데이터를 물리적인 제약없이 참조할 수 있어야 한다.
History of Database
데이터베이스가 등장하기 전부터 현재까지
Pre-computer
개인용 컴퓨터가 보급되기 전, 데이터들은 종이에 기록되었다. 원장과 파일에 기록되던 데이터들은 시간이 지날수록 많은 물리적 공간을 차지할 수 밖에 없었다. 양이 늘어나면 늘어날수록 관리하기가 힘들고 특정 데이터를 찾기위해서는 많은 시간을 할애해야 했다.

1960’s
컴퓨터 하드웨어 기술은 급속한 발전을 이루었다. 그 중 데이터베이스의 탄생에 큰 역할을 한 것은 기억장치들의 등장이다. 작지만 대용량의 정보를 기록할수 있는 반도체 기억장치(SRAM, DRAM)가 부품으로 사용됨으로써 컴퓨터의 크기는 줄어들고 대규모의 용량을 빠르게 다룰 수 있게 되었다. 1963년 Robert H. Norman을 통해 개발된 SRAM은 1965년부터 상업적으로 사용되기 시작했다. 그로인해 고객정보, 회계장부, 거래처 등의 정보를 캐비닛 속 파일에 보관하던 기업들은 기존의 아날로그 방식을 버리고 디지털화하기 시작했다.
* 최초의 상용 DBMS는 1964년 출시된 GE의 IDS(Integrated Data Store)이다.
* Disk에 관한 내용은 이 포스트에서 자세히 알아 볼 수 있다.
이 시기 유명했던 데이터베이스 시스템은 CODASYL과 IMS이다. 두 시스템은 서로 다른 데이터 모델을 사용하였는데 CODASYL은 네트워크형 데이터 모델을 IMS는 계층형 데이터 모델을 사용하였다.
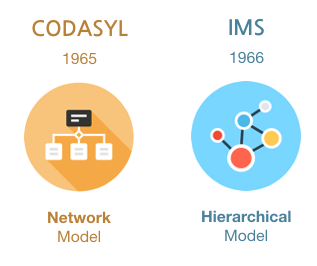 - 네트워크형 모델(Network Model)은 데이터베이스를 그래프 구조로 표현한다.
- 네트워크형 모델(Network Model)은 데이터베이스를 그래프 구조로 표현한다.
- 계층형 모델(Hierarchical Model)은 데이터베이스를 트리 구조로 표현한다.
- 1965 : CODASYL(Conference on Data Systems Lanaguages) [Graph 구조의 데이터베이스]
- 1966 : IMS(Information Manangement System) [Tree 구조의 데이터베이스]
CODASYL은 1959년 미국 국방부로 창설된 데이터 관리 시스템 및 언어 개발 기관이다. 1965년 CODASYL은 데이터베이스를 위한 DBTG(Data Base Task Group)를 설립한후 데이터베이스 관리 시스템(DBMS)을 개발하였다.
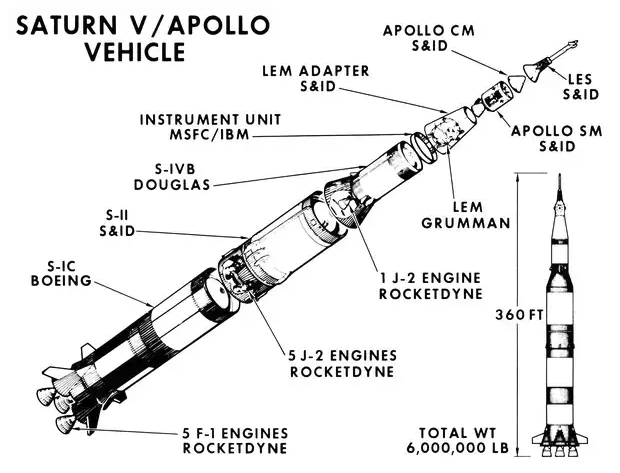
IMS는 IBM이 만든 DBMS로써 1966년도 아폴로(Apollo) 프로그램을 위해 만들어 졌다. 우주선 부품을 관리하는 용도로 만들어진 IMS는 아폴로 프로젝트를 성공하는데 일조하였다. 300만개가 넘는 부품으로 이뤄진 Saturn V 로켓은 IMS의 도움으로 1967년부터 1973년까지 총 13회 사용되었으며 27명의 우주인을 달에 보낼 수 있었다.
* Saturn V Rocket에 대해 흥미를 느낀다면 여기를 클릭.
1970’s
[Table 구조의 데이터베이스]
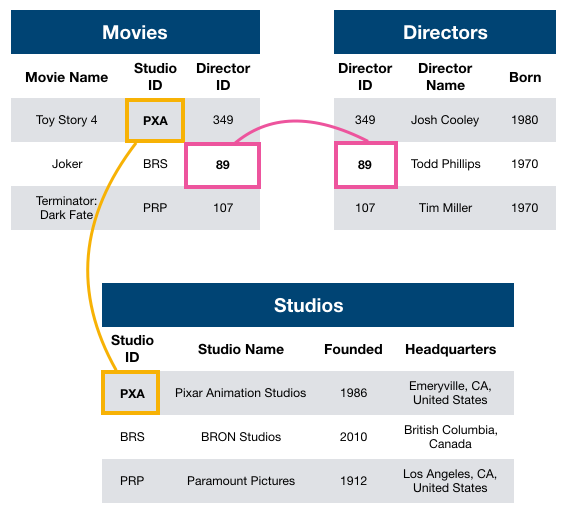
개인용 컴퓨터가 보급되기 시작한 1970년대에 들어서야 관계형 데이터 모델(relational data model)이 등장한다. 관계형 모델은 데이터베이스를 테이블의 집합으로 나타낸다.
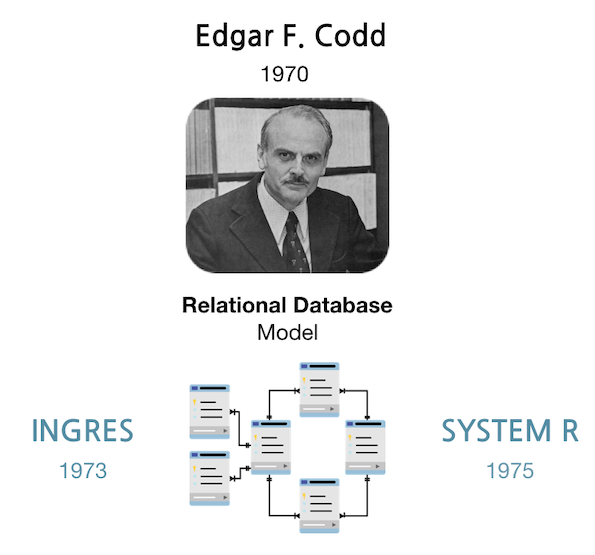
- 1970 : Relational Data Model San Jose의 IBM 연구소에서 근무하던 Edgar F. Codd는 그 당시 DBMS가 지닌 단점을 발견하였고 이를 대체할 수 있는 데이터 모델에 관한 연구를 진행했다. 네트워크형 모델과 계층형 모델은 실질적으로 큰 차이가 없었는데, 그래프(네트워크형)와 트리(계층형)형은 모두 포인터(pointer)를 이용해 데이터끼리 연결시키는 방식이기 때문이다. 두 모델의 DBMS는 빠르지만 융통성이 현저히 떨어졌다. 그는 1970년 Relation Model에 관한 논문(A Relational Model of Data for Large Shared Data Banks)을 발표한다.
- 1973 : Ingres 관계형 모델의 유용성을 알아본 UC Berkeley 의 Michael Stonebraker 팀은 Ingres 라는 DBMS를 만든다. 많은 회사들은 적은 비용으로 사용 가능한 Ingres를 이용하여 성공적인 DBMS를 만들어 내었다. Ingres를 통해 탄생된 시스템들은 MS SQL Server, Sybase, Wang’s PACE, 그리고 Britton-Lee가 있다.
- 1975 : System R IBM의 Donald D. Chamberlin과 Raymond F. Boyce는 SEQUEL을 사용하여 System R이라는 DBMS를 만든다. 비록 System 은 상용화 되지 못했지만 요즈음 사용하는 RDBMS의 대부분의 요소들을 갖춘 소프트웨어였다.
- 1976 : Entity-Relationshop Model 새로운 데이터 모델인 ER Model이 Peter Chen을 통해 만들어진다.
- 1977 : Oracle E.F.Codd의 아이디어에서 RDBMS의 가능성을 본 젊은 사업가 Larry Ellison은 IBM을 대적할 만한 회사를 차리고자 한다. 그는 자신의 돈 $2000(2019년의 $8,473.89에 해당하는 금액)을 투자하여 Bob Miner 그리고 Ed Oates와 함께 SDL(Software Development Laboratories) 이라는 소프트웨어 회사를 설립한다. 현재의 Oracle이다.
- 1979 : First RDBMS Oracle(그 당시의 RSI)은 IBM보다 앞서 첫번째 상용화된 RDBMS, Oracle V2를 시장에 내놓는다. IBM이 IMS성공에 취해 늦장을 부린 덕에 RDBMS로 큰 성공을 누릴 수 있었던 것이다.
* Edgar의 논문은 여기에서 볼 수 있다.
E.F.Codd 는 관계대수(Relational Algebra)를 이용한 관계형 모델을 만들어 내었다. 데이터를 포인터로 연결시켜 관리하는 대신 집합(합집합, 교집합 등)을 통해 관리하는 것이 더 실용적이라 생각했기 때문이다. 테이블 간의 관계를 기본키(Primary Key)와 외래키(Foreign Key)를 이용해 맺어주었다.
하지만 IBM은 관계형 모델을 밀어주지 않았다. 그 당시 IMS를 통해 막대한 수익을 올리고 있었기 때문이다. E.F.Codd 는 동료 C.J.Date와 함께 관계형 모델에 관해 글을 쓰고 여러 곳에서 강연을 다니게 된다.
* System R의 R은 Relation을 뜻한다.
* 사명은 SDL에서 RSI(Relational Software, Inc)로 1982년에는 RSI에서 Oracle로 변경된다.
* Oracel V1는 출시된 적이 없다. Oracle V2가 첫번째 제품인셈.

1980’s
1980년대는 네트워크형과 계층형 모델의 DBMS가 주류시장에서 밀려나고 관계형 데이터베이스가 대대적인 성공을 이룬 시기이다. SQL이 사실상의 표준이 되었으며 object-oriented 데이터베이스가 개발되었다.
- 1983 : IBM's DB2 Vs. Oracle V3 IBM에서 RDBMS인 DB2를 출시한다. DB2는 막대한 성공을 이루었고 IBM의 주력제품이 된다.
- 1984 : Sybase Sybase가 설립된다. 사이베이스는 Ingres 프로젝트에 참여했었던 Bob Epstein이 만든 회사로서 오라클의 경쟁자로 성장하게 된다. 추후 MS사의 MS-SQL은 사이베스를 기반으로 제작된다.
- 1985 : OODBMS 1985년 관계형 데이터베이스의 약점을 보완한 Object-oriented DBMS가 세상에 모습을 드러냈다. 하지만 이 당시 OOP(객체지향 프로그래밍)와 멀티미디어(OODBMS는 CAD, CAM, CIM등과 같은 고급 어플리케이션에 사용되기에 적합하다)가 유명세를 타지 않았기에 OODBMS는 그다지 주목을 받지 못했다.
- 1986 : Postgres Postgres의 등장. Ingres 의 상용화를 위해 버클리를 잠시 떠났던 Michael Stonebraker 교수는 1985년 버클리로 돌아와 학생들과 함께 Postgres 프로젝트를 진행한다. In-gres의 후속작 Post-gres(POST inGRES)는 1986년도에 출시된다.
오라클은 C로 작성한 Oracle V3를 출시한다. 트랜젝션을 위한 COMMIT과 ROLLBACK을 지원하는 제품이다.
* 2010년 독일의 SAP회사에 인수되게 된다.

1990’s
1990년대는 Tim Berners-lee가 발명해낸 WWW를 기반으로 인터넷이 전세계적으로 보급되었다. 인터넷 사용자 수의 증가는 데이터의 급속한 팽창을 불렀다.
- 1990 : Data Warehouse Red Brick Systems가 Red Brick Warehouse 를 소개한다.
- 1991 : Key-value Database 오픈소스 key-value형 Berkeley DB가 등장한다. Hash access 방법을 지원한다.
- 1992 : Multidimensional Databse 다차원 배열형태의 데이터 구조를 사용하는 Multidimensional DBMS인 ESSBASE의 등장.
- 1993 : Column-oriented Database 컬럼 기반 데이터베이스가 개발되었다.
- 1996 : MySQL MySQL이 공개된다.
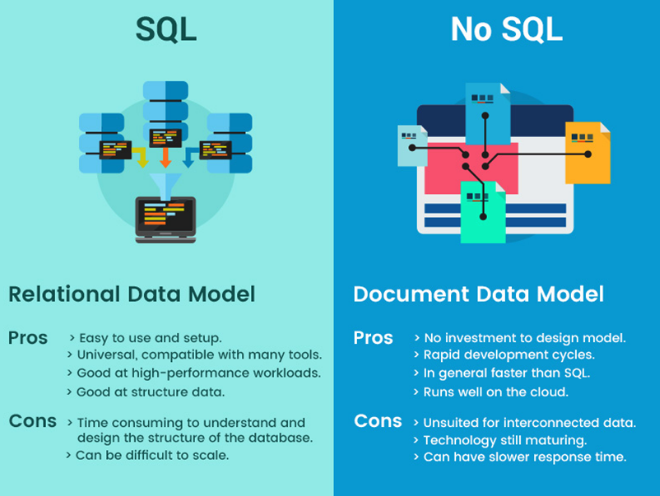
- 1998 : NoSQL Carlo Strozzi 는 기존 RDBMS의 수평적 확장성(Horizontal Scalability)에 대한 문제를 발견하였다. 그리하여 높은 확장성을 지닌 NoSQL(not only SQL)을 만들어낸다.
방대한 양의 데이터를 효율적으로 관리하기 위한 방법이 필요하였고 그로인해 Data Warehousing이 관심을 받게 된다.
2000’s
2000년대에 데이터베이스 시장을 주름잡았던 3대 회사는 Microsoft, IBM 그리고 Oracle이다.
- 2000 : Berkeley DB XML 오라클사의 Berkeley DB XML 출시. XML(eXtensible Markup Language Data) 데이터를 다룰 수 있는 DB이다. XPath를 질의어로 사용한다.
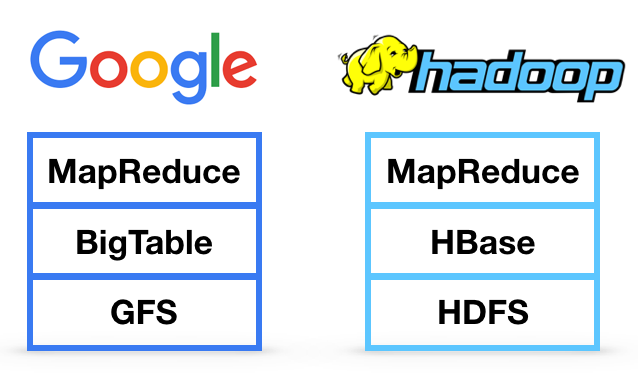
- 2004 : Google's BigTable Google 에서 컬럼기반(column-oriented) 데이터베이스인 BigTable를 소개한다. 분산 데이터 처리를 위한 MapReduce기술을 사용한다.
- 2006 : Apache Hadoop Hadoop은 Doug Cutting이 구글의 GFS 논문을 참고하여 만든 오픈소스 소프트웨어이다. 구글을 대항하기 위해 만들어진 하둡은 빅테이터 시대를 이끌게 된다.
- 2007 : MongoDB MongoDB가 설립된다.
- 2008 : Cassandra Cassandra는 Avinash Lakshman과 Prashant Malik가 만든 NoSQL 분산형 데이터베이스이다. 빅데이터를 저장하고 관리하기 위해 개발되었다. Google의 BigTable과 Amazon Dynamo라는 핵심 기술을 모두 갖고 있는 DB이다.
* MapReduce, GFS(Google File System)등은 다른 포스트에서 자세히 다룰 예정이다.
* Hadoop 또한 다른 포스트에서 다룰 예정이다.
Today
데이터베이스는 시대의 흐름에 맞게 진화를 거듭해 왔다.
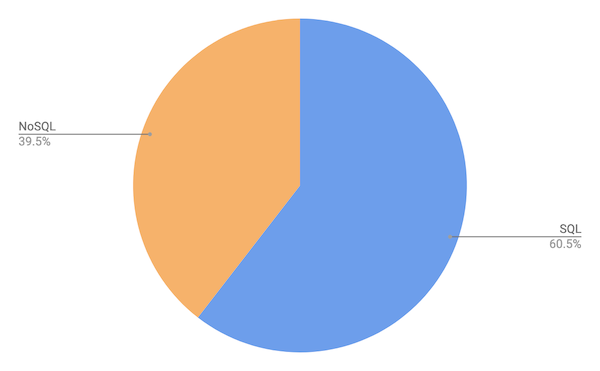
Scalegrid 조사에 따르면 2019년 SQL과 NoSQL의 사용 비율은 아래와 같다.
SQL : 60.48%
NoSQL : 39.52%
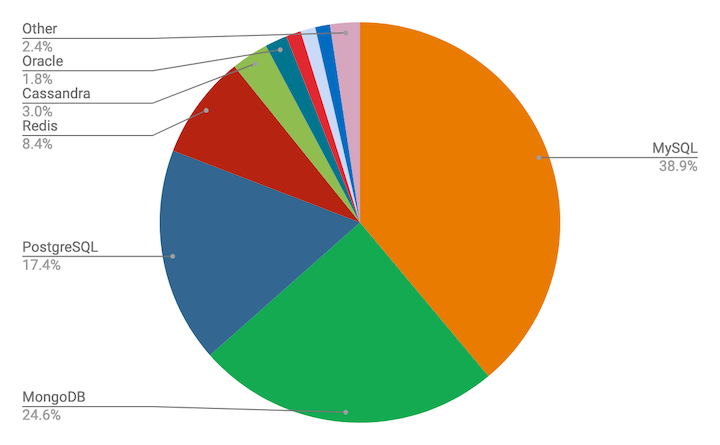
다음은 DB의 점유 비율이다.
선두주자는 MySQL로써 38.9%를, 그 뒤를 MogoDB(24.6%)와 PostgreSQL(17.4%)이 잇고 있다.
References
- 2019 Database Trends – SQL vs. NoSQL, Top Databases, Single vs. Multiple Database Use
- A Brief History of PostgreSQL
- A Timeline of Database History
- An Introduction to Data Base Design
- Architecture of a Database System
- Berkeley DB
- Column-Oriented Database Systems
- Databases and data capture
- Data Warehousing Fundamentals for IT Professionals
- Donald D. Chamberlin
- Evolution Of Databases – A Fascinating Journey!
- File systems and databases: managing information
- History of Databases
- History of personal computers
- How many parts were in a Saturn V rocket, including the command and lunar modules?
- IBM Information Management System
- Important Papers: Codd and the Relational Model
- Inflation Calculator
- Introduction to Oracle Database
- Larry Ellison
- Performance based Comparison between RDBMS and OODBMS
- Random-access memory
- Saturn V Rocket
- System Properties Comparison Ingres vs. PostgreSQL
- System R & DBMS Overview
- WHERE ARE THEY NOW? Look What Happened To The Co-founders Of Oracle